Graphbook
Graphbook is an open source framework for building scalable and visual AI applications written in Python. You should use Graphbook if you want to simplify the development of AI applications that need to be scalable, observable, and interactive with a fresh-looking UI.
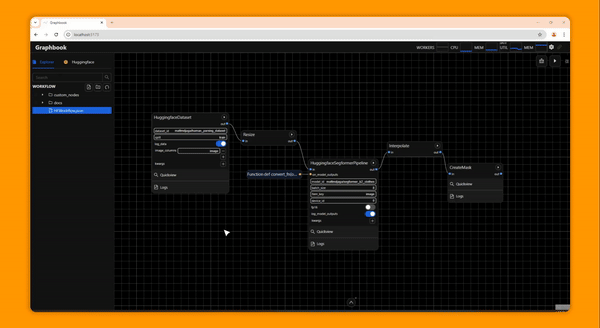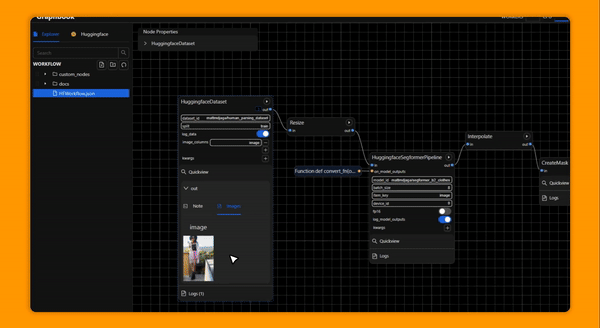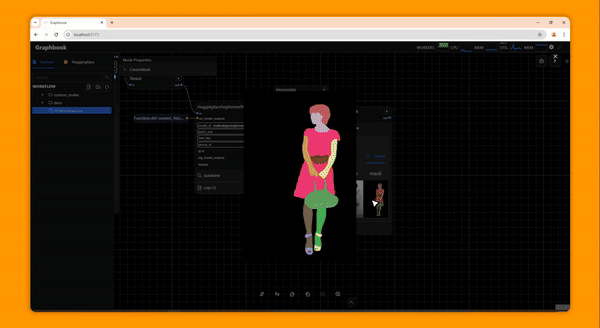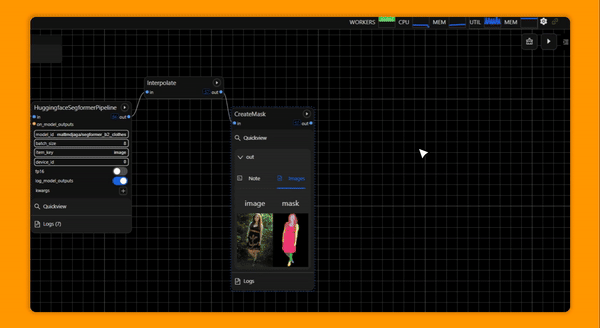
Example Applications
Clean and curate custom large scale datasets
Demo ML apps on Huggingface Spaces
Build and deliver customizable no-code or hybrid low-code ML apps and services
Quickly experiment with different ML models and adjust hyperparameters
Maximize GPU utilization, parallelize IO, and scale across clusters
Wrap your Ray DAGs with a frontend for end users
Features
Graph-based visual editor to experiment and create complex ML workflows
Workflows can be serialized as Python and JSON files
Caches outputs and only re-executes parts of the workflow that changes between executions
UI monitoring components for logs and outputs per node
Custom buildable nodes with Python via OOP and functional patterns
Multiprocessing I/O to and from disk and network
Customizable multiprocessing functions
Ability to execute entire graphs, or individual subgraphs/nodes
Ability to execute singular batches of data
Ability to pause graph execution
Basic nodes for filtering, loading, and saving outputs
Node grouping and subflows
Autosaving and shareable serialized workflow files
Registers node code changes without needing a restart
Monitorable system CPU and GPU resource usage
Monitorable worker queue sizes for optimal worker scaling
Human-in-the-loop prompting for interactivity and manual control during DAG execution
Can switch to threaded processing per client session for demoing apps to multiple simultaneous users
Scale with Ray: Build all-code workflows and scale pipelines on Ray clusters
(BETA) Third Party Plugins
Why
In developing ML workflows for AI applications, a number of problems arise.
See also
1. Multiprocessing
We want to have enough IO speed to keep our GPU from being underutilized. GPUs cost a lot more money than CPUs, so it is important to scale the number of worker processes to load and dump data from and to IO.
Graphbook takes care of this by setting up worker processes that can perform both the loading and dumping. Additionally, users can monitor the performance of workers, so that they can know when to scale up or down.
2. Batching
To take full advantage of the parallel processing capabilities of our GPU, we want to batch our units of data to maximize efficiency of our workflows. This is done with Pytorch’s builtin Dataset and Dataloader class, which handles both the multiprocessing and batching of tensors, but our input data is not just tensors. Each entity that flows in a pipeline can be supplemented with properties such as attributes, annotations, and database IDs. While we process, we need to load and batch what goes onto our GPU while knowing about the entirety of the entity.
Thus, we have a specific batching process that allows our nodes to load and batch along an individual property within a Python dict while still holding a reference to that belonging dict.
3. Fast, Easy Iteration
Our workflows need to be able to be changed quickly due to many factors, and our software engineers aren’t the only ones with the know-how on how to fix things. We need an easy and accessible approach to declare our workflows and adjust its parameters, so that we can quickly iterate while giving the opportunity to adjust the logic of our workflows to anyone.
Software engineers build modular nodes in Python by extending the behavior of Graphbook processing nodes, and then, with our web-based UI workflow editor, anyone can manage the no-code interface with the custom built nodes that were previously written in Python.
4. Evaluation
It is difficult to estimate the performance of models in the wild. While a model is in production, it processes unlabeled data and we are supposed to trust its autonomous outputs. Furthermore, the output of generative AI is normally subjective. There is no straightforward way to accurately measure the fidelity or textual alignment of AI generated images. Thus, we need an approach to monitor the quality of our ML models by “peeking” into their outputs with human observation.
Through its web UI, Graphbook offers textual and visual views of the outputs and logs of each individual workflow node and allows the user to scroll through them.
5. Flexible Controls
While experimenting with models and iterating upon the development of our ML workflows, we want our workflow to be interactive and offer the user complete freedom on how our graphs are executed. That means we need to be able to run singular batches and observe the output without having to write custom code to do so. When something seems to be going wrong, we want to be able to pause the current execution and diagnose the issue. When we want to focus on the development or observe a particular subgraph (or singular node) amongst a much larger graph, we want to be able to execute it without running or affecting the rest of the graph.
Graphbook supports pausing a currently executing workflow, execution of a particular subgraph, and “stepping” through a node which runs a node’s parent dependencies and itself until the node produces an output. It supports all of these controls without forcing the developer to write any more code.
6. Caching
If a node has executed before, we want to cache its results, so that outgoing nodes can use those previously generated results. This saves us a lot of processing time because we don’t have to re-execute parts of the graph that weren’t changed while working on other parts of the graph.
In Graphbook, each of the nodes have cached results and will only be cleared if the internal Python code from that node changes, its parameters change, or if they are manually cleared by a user. Currently, the results are cached in memory which makes it fast but very limited, so we have plans to adopt an external solution.
7. Open Source
Most importantly, we need such a solution to be open source while offering a way to manage our own deployments because we are working with proprietary data. We need to stay away from commercial platforms or services that force us to trust in their business practices to keep our data private and secure.
Graphbook is completely free and open source and can be deployed anywhere. We offer the source on GitHub and maintain PyPI packages and container builds.