Ray
Build distributable Ray Apps with Graphbook!
Ray is a distributed computing framework that allows you to scale your workflows across multiple machines. You can build Ray DAGs in Python code using Graphbook’s API which provides a wrapper around each node, so that your applications can have the following capabilities:
Node Parameters: Define parameters for each node and configure them in the UI
Multi-Output Nodes: All nodes have named output bindings that can be individually connected to by other nodes
Node Documentation: Docustring from each node class is displayed in the UI
Monitoring: Monitor logging and performance of each node in the UI
Output Visualizations: Visualize outputs and images coming from each node.
Although using Ray can make your applications more scalable, there are some limitations to be aware of. See Current Limitations.
Getting Started
To get started, install Graphbook along with the graphbook.ray dependencies with:
$ pip install graphbook[ray]
Using the RayExecutor
Follow the guide in Python-Defined Workflows to create a DAG.
All Graphbook DAGS can be executed using the RayExecutor (graphbook.ray.RayExecutor).
To use the RayExecutor, simply pass it to graphbook.Graph.run() method like so:
import graphbook as gb
from graphbook.ray import RayExecutor
g = gb.Graph()
@g()
def _():
...
if __name__ == "__main__":
g.run(executor=RayExecutor())
To run the app, execute the script:
$ python myapp.py
To keep the web app running after execution is finished, you can add the following code to the end of your script:
...
if __name__ == "__main__":
g.run(executor=RayExecutor())
import time
try:
time.sleep(999999)
except KeyboardInterrupt:
pass
And view your outputs in the web app by navigating to http://localhost:8005 in your browser.
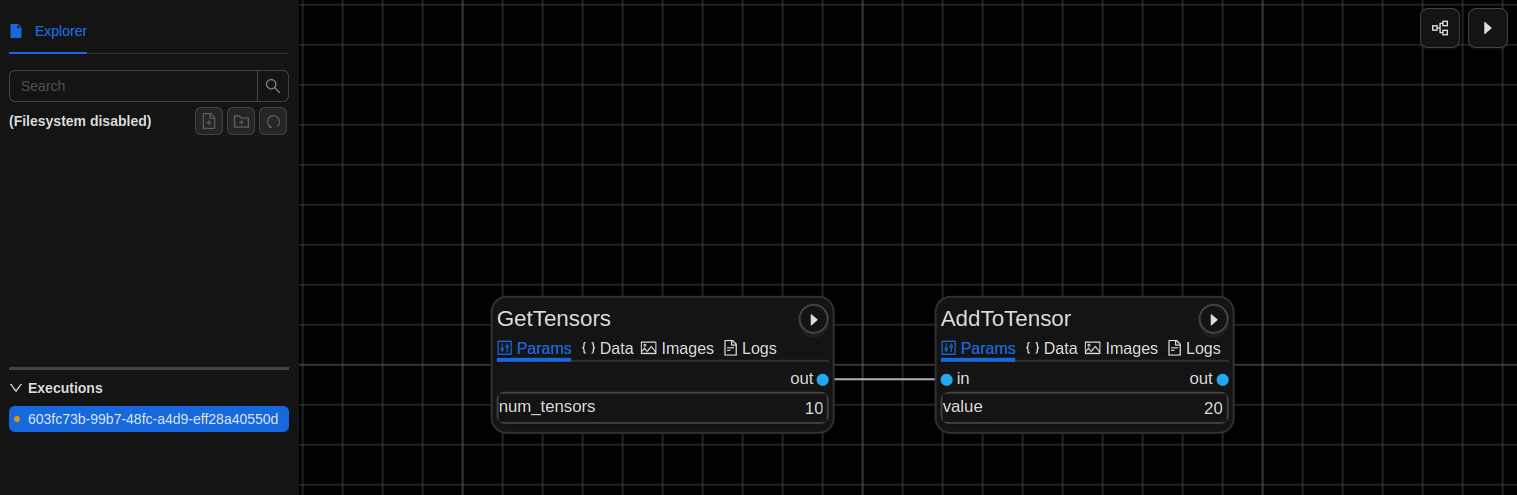
The RayExecutor will convert all steps and resource into Ray Actors that is compatible with Graphbook. All node types can be used in Ray DAGs as well except for the ones listed in Current Limitations.
Deploy to a Ray Cluster
To deploy your Ray DAG to a Ray cluster, you must already have a Ray cluster running. See Ray’s documentation for more information on how to set up a Ray cluster.
Once you have a Ray cluster running, your script will have the following changes:
start_web_server: Set to
Falseto prevent the web server from starting on the cluster.executor must have the following:
address: The address of the Ray cluster.
log_dir: A persistent storage location for logs.
The example below uses an S3 bucket for log storage, and you can assume this cluster is in AWS:
import graphbook as gb
from graphbook.ray import RayExecutor
g = gb.Graph()
@g()
def _():
...
if __name__ == "__main__":
executor = RayExecutor(
address="<cluster_address>",
log_dir="s3://my-bucket/logs"
)
g.run(executor=executor, start_web_server=False)
While it is executing, you may view the graph execution in realtime with:
$ graphbook view s3://my-bucket/logs
The view subcommand will run a graphbook server that will simply read the logs of a given directory or S3 url.
Current Limitations
Nodes created as functions are not yet supported. You must use classes for now.
Execution is synchronous as opposed to the default asynchronous execution that is offered by Graphbook. This may slow down troubleshooting of problems that may happen deeper in the DAG.
Only one DAG execution can be constructed at a time.
Currently unsupported features with Ray DAGs, but will be supported in the near future:
Prompting:
graphbook.steps.PromptStepis not yet supported.Batching:
graphbook.steps.BatchStepis not yet supported but can be easily implemented by the user since execution is synchronous. Feel free to parallelize loading and dumping I/O with regular ray tasks.Streaming/Generator Source Steps:
graphbook.steps.GeneratorSourceStepis not yet supported due to the limitations of Ray DAGs. This means you cannot use generators to asynchronously yield data in source nodes when building Ray DAGs with Graphbook.Workflow Documentation: is not yet supported. Node documentation is still supported.